近期我在排查线上 K8S 环境下 Java 服务 OOMKilled 问题时,遇到了一些超出预期的现象。这给了我一个重新学习 JVM 内存管理机制、Linux 底层 glibc 内存分配器以及审视系统架构设计的机会。在此记录一下整个排查与优化的过程。
本文涉及的主要依赖版本如下:
- Java:JDK 17 (采用 ZGC)
- glibc:标准 Linux glibc
- 环境:Kubernetes / Docker
背景与问题
出问题的应用是一个系统管理员使用的 HTTP REST API 服务(非核心服务,并发不高)。
K8s的资源配置如下:
1 | resources: |
启动应用时使用的主要 JVM参数如下:
1 | - '-XX:+UseZGC' |
现象是在凌晨高峰期(请求并发量为平常的2倍),Pod 经常被 K8S 以状态码 137 (OOMKilled) 终止。检查日志,没有发现任何 Java 层面的 OutOfMemoryError 异常。
排查误区:K8s QoS 机制与 OOMKilled 的区别
由于没有发现JVM层面的OOM,所以我第一反应是 K8s 资源配置不合理导致 Pod 被驱逐。我们简单回顾下 Kubernetes QoS Class:
QoS(Quality of Service)是 K8s 根据 Pod 的资源配置自动分配的服务质量等级,决定节点资源紧张时 Pod 被驱逐的优先级。
| 等级 | 驱逐顺序 | 特点 | 适用场景 |
|---|---|---|---|
| Guaranteed | 最高优先级 | 资源得到完全保障,最后被驱逐,适合核心业务服务 | 数据库、核心微服务 |
| Burstable | 中等优先级 | 有基础保障但可以弹性扩展,中等驱逐风险,适合普通应用 | 普通 Web 应用 |
| BestEffort | 最低优先级 | 尽力而为,无任何资源保障,最先被驱逐,适合非关键任务 | 批处理、测试任务 |
当时该服务的等级为 Burstable。为了排除“节点资源不足导致被无辜驱逐”的可能,我将 requests 提升至与 limits 一致,使其 QoS 变为 Guaranteed:
1 | resources: |
然而过了一天,发现 Pod 依然 OOM。这时我意识到自己陷入了一个认知盲区:K8s 的 OOMKilled (Exit Code 137) 是由 Linux Cgroup 层面的严格限制触发的。当 Pod 的总体物理内存使用量(RSS)超过了 limits.memory(即 2GB),无论 QoS 是什么级别,都会被操作系统直接 Kill 掉。QoS 仅仅影响节点物理内存不足时的驱逐(Eviction)顺序,无法拯救 Pod 自身越界引发的 OOM。
查看 Pod 资源监控,证实了内存使用确实超出了 2G 的硬性限制:
JVM 内存剖析:消失的 700MB 去哪了?
为了追踪 JVM 内存的使用情况,我开启了 Native Memory Tracking (NMT):-XX:NativeMemoryTracking=summary。
启动初期的 NMT 输出如下:
(省略部分输出…)
1 | Total: reserved=57916MB, committed=1347MB |
疑问一:为什么 1GB 堆的 reserved 高达 49152MB?
这是 ZGC 独有的 “多重映射”(Multi-Mapping) 技术(用于实现着色指针 Colored Pointers),它会将同一块物理内存映射到虚拟地址空间的 3 个不同位置(Remapped, Marked0, Marked1)。所以 49152MB ≈ 1024MB × 3 × 16 只是虚拟地址空间的预留,并不消耗真实的物理内存或 swap。
疑问二:物理内存去哪了?
已知 JVM 的堆内存(1GB)、元空间(~100MB)、CodeCache 等总和约为 1.3GB。那么 K8S 限制的 2GB 中,剩余的大约 700MB 物理内存去哪了?
在 ZGC 场景下,GC 自身的元数据(如 Live Map、Forwarding Table 等)开销极大。尤其在堆被打满且包含较多大对象时,转发表(Forwarding Table)极度膨胀。保守估算,在高峰期 ZGC 的 GC 域 committed 物理内存可能会冲到 200MB ~ 400MB。但这仍然无法完全解释剩下所有内存的去向。
G1 与 ZGC 的真实占用怎么看?
这可以查看这篇文章:容器环境下 G1 与 ZGC 内存统计差异与虚高溯源
700MB 内存拆解计算模型
以下是在 1核、1GB 堆 + 2GB 容器限制 + ZGC + 高并发网络 IO 场景下的估算模型:
| 内存区域 | 估算公式 / 依据 | 正常峰值 | 高峰极端值 |
|---|---|---|---|
| Java Heap (committed) | -Xms1024m / -Xmx1024m |
~700 MB | ~1024 MB |
| ZGC GC元数据 (Live Map + Forwarding Table) | 约为堆大小 × 8%~35%(大对象越多越高) | ~80 MB | ~360 MB |
| Metaspace | -XX:MaxMetaspaceSize=192M |
~120 MB | ~180 MB |
| CodeCache | -XX:ReservedCodeCacheSize=64M |
~30 MB | ~60 MB |
| Direct Memory | -XX:MaxDirectMemorySize=256M |
~40 MB | ~256 MB |
| glibc Arena碎片 (8 Arena × 128MB) | MALLOC_ARENA_MAX = 8 × nproc,1核 → 上限 8 个 Arena |
~256 MB | ~512 MB |
| JVM线程栈 | 每线程约 512KB~1MB × 线程数约200 | ~100 MB | ~200 MB |
| 总计 | — | ~1366 MB | ~2592 MB ❌ OOM |
核心发现:堆内与堆外的双重危机
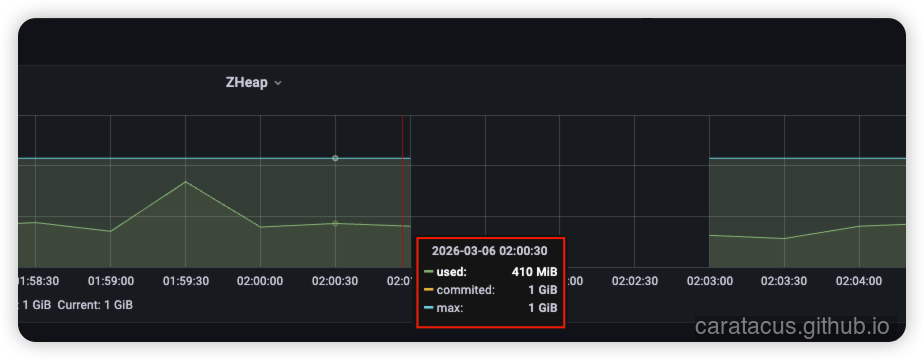
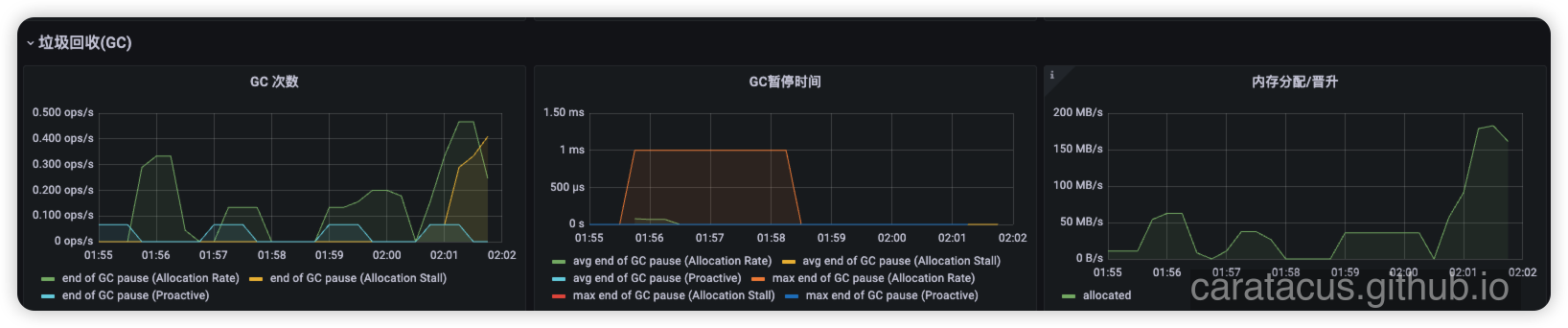
在监控中,02:00 到 02:01 期间发生了剧烈异动,这里暴露出了两路并发危机:
1. 堆内危机:Allocation Stall (分配停顿)
- 现象: 内存分配率(allocated)瞬间从几十 MB/s 飙升至 200 MB/s。随后,代表
Allocation Stall的黄线急剧上升。 - 本质: ZGC 是一款并发垃圾回收器,但当业务线程分配内存的速度,远远超过了 ZGC 回收内存的速度时,1GB 的堆被彻底塞满。ZGC 不得不强行挂起业务线程,等待内存释放。这说明 Java 堆内存已经处于极度高压状态。
2. 堆外危机:glibc 内存碎片
- 现象: 结合业务逻辑,服务崩溃前有一个数据聚合接口被高频调用,该接口会向外部发起 30+ 次 HTTP 请求,每次响应体 1~2MB。
- 本质: 高并发的网络 HTTP 请求意味着底层需要创建大量的 Socket 连接,并使用 NIO 分配大量的直接内存(Direct Memory)。根据 OpenJDK 官方缺陷记录 JDK-8193521,默认情况下,
glibc的内存分配器 ptmalloc2 采用多 Arena 机制来减少多线程下的锁竞争。其工作原理如下:- 每个线程在调用
malloc时,会尝试对 Arena 加锁(Try-Lock),若成功则使用该 Arena 分配内存; - 若当前 Arena 已被其他线程锁定,glibc 会尝试其他已有 Arena,若全部被锁则创建一个新 Arena;
- Arena 上限为:32 位系统 =
2 × CPU核数;64 位系统 =8 × CPU核数。在 1 核容器中,上限为 8 个 Arena; - 每个 Arena 的内存通过
mmap分配独立匿名段,64 位系统默认每段约 64~128 MB; - Arena 一旦创建不会归还给 OS(除非显式调用
malloc_trim),即使线程退出,内存也滞留,这是碎片的根源。
- 每个线程在调用
正是这几十个并发网络 IO 线程(如 Tomcat/Netty 线程池)频繁竞争 glibc Arena,迅速将 Arena 打满至上限 8 个,产生多达 8 × 128MB = 1GB 的虚拟内存预留,以及几百 MB 的碎片化物理内存占用。加上 ZGC 昂贵的元数据开销,彻底吃干了容器剩余的 700MB 物理内存,最终引爆了 K8S 的 OOMKilled。
架构选型反思:G1GC vs ZGC
在排查初期,我曾推测是否可以通过将垃圾回收器切换为 G1GC 来缓解内存压力,但当时我认为 1~2MB 的对象会导致 G1 产生大量的 Humongous Object(大对象),从而引发 Full GC 或 Mix GC,所以放弃了。
这是一个典型的技术盲区。 事实上:
- G1 的 Region 大小是可以通过
-XX:G1HeapRegionSize=4M或8M来手动配置的。只要配置得当,1~2MB 的对象就可以正常进入年轻代(Eden),完全避免 Humongous Object 的问题。 - ZGC 在小内存容器中过于“奢侈”:ZGC 的设计初衷是针对 TB 级大堆和超低延迟。在 1GB 极小堆且容器硬性限制为 2GB 的场景下,ZGC 高达几百兆的元数据开销(各类 Map 和表格)占比过大,反而严重挤压了业务和操作系统的生存空间。
起初我推断,在这种严苛的资源约束下,G1GC 实际上是比 ZGC 更务实的架构选择。但这在后续的实验测试推翻了这一假设。
方案一:业务逻辑重构(最高优先级,治本之道)
强依赖 JVM 调优和底层 C 库替换是治标不治本。面对一次性聚合 30 个 1~2MB 响应的场景(瞬时占用 60MB+),根本问题是内存中积压了太多大对象。
- 重构策略: 引入流式处理(Streaming / Reactive) 或 分页拉取。例如使用 WebClient/WebFlux 边读边写,或者分批次请求外部接口并落盘暂存,避免将巨大的响应体同时 hold 在堆内存中。
方案二:推测与验证:JVM 垃圾回收器降级与调优
针对前述对于 G1GC 优势的推测,我在测试环境中进行了垃圾回收器降级的实验,回归 G1GC:
- 测试环境调整的 JVM 参数:
1
2
3
4
5
6
7
8
9
10-XX:+UseContainerSupport
-XX:MinRAMPercentage=65.0
-XX:MaxRAMPercentage=65.0
-XX:InitialRAMPercentage=65.0
-XX:+UseG1GC
-XX:MaxGCPauseMillis=100
-XX:G1HeapRegionSize=4M
-XX:MaxMetaspaceSize=192m
-XX:MaxDirectMemorySize=256m
-Xlog:gc*:file=logs/gc.log:time,uptime,level,tags:filecount=7,filesize=100M
然而,通过观察压测期间的 gc.log 日志与监控,我发现了以下严重问题:
1. 致命痛点一:“巨型对象”分配 (Humongous Allocation)
由于参数 -XX:G1HeapRegionSize=4M 的配置,G1 将堆内存划分为了大小为 4MB 的 Region。
- 在 G1 GC 的规则里,只要一个对象的大小超过了 Region 大小的一半(也就是 2MB),它就会被判定为巨型对象。
- 当前应用正在频繁地创建大于 2MB 的大对象。
- G1 对待巨型对象非常苛刻:它必须在老年代中寻找连续的 Region 来存放它们,并且每一次分配巨型对象,都会直接触发一次全局的并发标记周期。
2. 致命痛点二:单核 CPU 被极其漫长的“并发标记”拖垮
截取测试期间 GC 日志中一次典型的并发标记周期耗时:
GC(70) Concurrent Mark Cycle 1553.249ms
一次并发标记周期竟然长达 1.55 秒。在这份日志里,几乎每一次并发标记都要花费 1 到 1.5 秒的时间。
根本原因:容器只有 1 个可用 CPU。G1 原本设计用来在后台多线程飞速运行的并发标记任务,被迫只能排成一条单线慢慢跑。在这漫长的 1.5 秒里,虽然应用没有完全停顿,但 CPU 资源被 GC 严重抢占,业务请求出现了严重的延迟抖动。
3. 致命痛点三:过山车式的“堆内存伸缩”

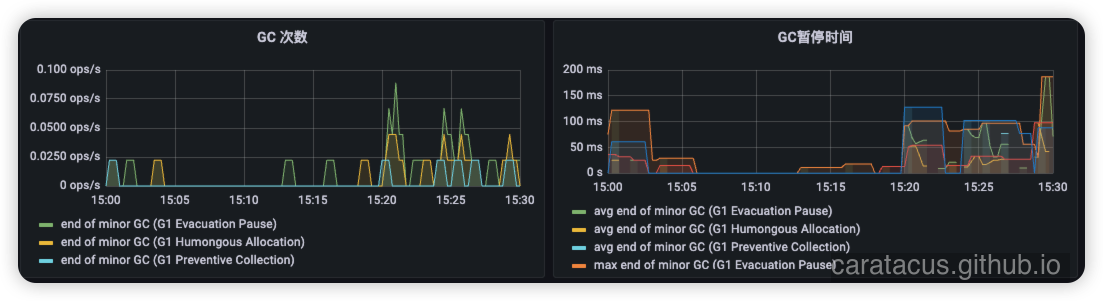
观察上述监控数据发现,随着巨型对象的涌入,堆内存频繁触发扩缩容(G1自适应调整 Old 区与 Eden 区大小)。这种剧烈的“堆内存伸缩”会消耗大量操作系统资源,导致应用出现卡顿。
针对此现象,可以通过增加以下参数来约束 G1 的自适应行为:
1 | -XX:G1HeapRegionSize=8M |
对于更多G1垃圾回收器参数调优,可以查看Garbage First Garbage Collector Tuning
不过,基于上述并发标记耗时与堆内存剧烈波动的验证数据,我最终放弃了切换至 G1GC 的方案,维持 ZGC 的使用。
方案三:底层 OS 内存分配器优化(最低优先级,兜底方案)
针对 glibc 的多 Arena 碎片问题,有两个方向可以尝试:
- 限制 Arena 数量:
通过配置环境变量export MALLOC_ARENA_MAX=1(或 2、4)。实测发现该参数确实能强制降低内存碎片,但在高并发网络 I/O 下,会导致线程在分配内存时面临严重的锁竞争(Lock Contention),引起 CPU 使用率飙升,属于用 CPU 换内存的妥协之举。 - 替换为 jemalloc/tcmalloc:
jemalloc通过维护带有不同大小桶(buckets)的 Arena,能更有效地控制内存碎片率,同时针对多线程并发进行了优化,减少了锁竞争。这是比调整MALLOC_ARENA_MAX更优雅的底层解决方案。
终极解决与优化方案
理清了前因后果,从架构和系统层面,我制定了优先级自上而下的解决方案:
解法与危机映射说明:
- 堆内危机(Allocation Stall) → 方案一(减少大对象堆积)
- 堆外危机(glibc Arena 碎片) → 方案三(换 jemalloc 或限制 Arena 数量)
效果验证
考虑到改造成本,本次优化最终采用临时限制 Arena 数量的兜底方案,系统在后续的日子里表现得到了根本性改善:

| 指标 | 优化前(高峰期) | 优化后(高峰期) | 改善效果 |
|---|---|---|---|
| Pod RSS 内存占用 | ~2.1 GB(超限 OOMKilled) | ~1.4 GB | ↓ 40% |
| OOMKilled 频率 | 高峰期每天 1~2 次 | 0次 | ✅ 彻底消除 |
| glibc Arena 数量 | 8个(上限) | 1个 | ↓ 85% |
优化后的 Pod 内存监控曲线平稳,彻底告别了内存爬升引发的 OOMKilled 问题。关于频繁创建大对象的问题,已反馈给业务团队进行后续的调整与优化。
架构演进与反思
本次排查暴露了云原生环境下的内存问题,往往是堆内业务不合理与堆外基础设施机制冲突的综合产物。这要求在架构设计时,需提前预见业务层面的低效设计对底层基础设施产生的压力。优先从业务架构设计上解决问题,而非单纯依赖底层组件的调优,才是保障系统稳定性的根本途径。
参考资料