本文是 Spring Cloud Gateway 堆外内存泄漏排查(上) 的续篇。在上篇中,我定位到了自定义 Filter 中使用 .buffer() 操作符导致堆外内存泄漏的问题,并将方案调整为 DataBufferUtils.join()。
补充下之前遗漏的主要依赖版本:
- Spring Cloud Gateway Server:3.1.4
- Reactor Netty Core:1.0.24
1. 泄漏重现与监控状态
在首次修复上线一周后,观察内存监控数据发现 Direct Buffers 的增长速度确实比修复前放缓了许多。然而,系统仍再次抛出 Netty 内存泄露的告警,Direct Memory 依然呈现出缓慢的线性增长趋势。
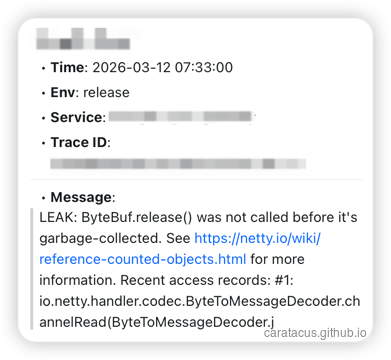
Netty 的 ResourceLeakDetector 再次输出了泄漏报告:
1 | [ERROR] io.netty.util.ResourceLeakDetector - |
从监控图表中同样可以看到,Direct Buffer 的增长速度确实比修复前慢了很多,但水位线仍在不断抬高。
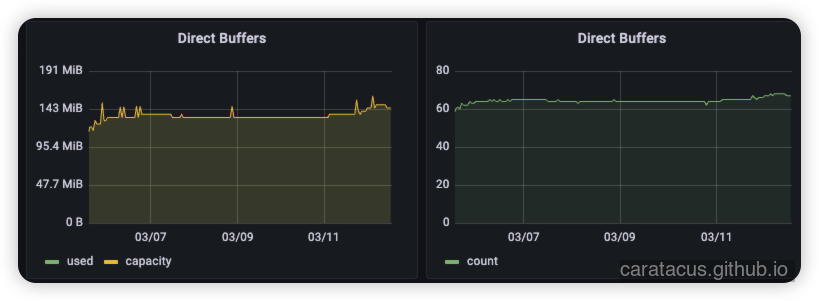
对比之前的状态,可以得出两项客观结论:
- 首次修复显著降低了泄漏频率:修复前 2 天内出现 17 条 leak records,当前 7 天内仅出现 7 条。
- 泄漏链路的根因仍未完全消除:泄漏抛出的位置,依然集中在处理下游微服务响应阶段的数据解码过程。
2. 代码溯源与防守盲区
回顾并重新审视首次修复后的代码,我发现原有的异常处理与类型推断仍存在逻辑盲区。此前为了替换 Flux.buffer(),我引入了 DataBufferUtils.join(),但释放逻辑并没有覆盖到所有的异常分支。
展示首次修复后仍带有缺陷的代码片段:
1 | // 首次修复后的代码,仍有缺陷 |
这段逻辑存在两处隐患:
- 缺乏异常兜底:当
dataBuffer.read(content)或随后的数据转换方法抛出异常时,流将被中断,导致DataBufferUtils.release(dataBuffer)无法执行。 - 类型判断过于武断:使用
if (body instanceof Flux)忽略了Mono类型的场景。若上游传递的是Mono,请求将直接走return super.writeWith(body)分支,绕过了自定义的处理逻辑,可能引发其他异常行为。
为了消除这些盲区,我进行了第二次重构,引入了 try-finally 块确保释放,并使用 Flux.from() 统一封装 Publisher:
1 | // 统一封装并使用 try-finally 确保 Buffer 必然被释放 |
将上述改进部署至测试环境。然而,在经过数天的压测与观察后,遗憾的是,Direct Buffers 缓慢增长的现象依然存在。代码层面的显式遗漏已被修补,我逐渐开始怀疑泄漏可能隐藏在更深层的框架交互中。
3. 社区关联 Issue 研判
在自身的代码排查陷入瓶颈后,我转向梳理 Spring Cloud Gateway 与 Reactor Netty 社区的 Issue 记录。研读大量相关讨论后,我发现这是一个在此架构组合下极其普遍且难以根除的顽疾。针对收集到的大量 GitHub Issue,我将其归纳为以下三种引发 ByteBuf.release() 泄漏的核心场景:
- 请求体缓存机制导致的引用丢失
多位开发者在缓存 Request Body 时遇到问题:当新旧 Key 覆盖或流式处理被打断时,底层 ByteBuffer 丢失了具体的指向引用,导致无法被回收(参考文末 Issue #2408、#2672、#1188)。不过这个问题之前就有了解过,所以很早就调整过相关源码,这个问题不是我当前遇到的问题。 - 官方修改请求/响应体过滤器的原生缺陷
部分 Issue 明确指出,在使用官方的ModifyRequestBodyGatewayFilterFactory和ModifyResponseBody过滤器时,同样会持续遭遇 ByteBuf 泄漏(参考文末 Issue #3376、#3797)。社区给出的唯一可靠解决方案是:无论使用何种拦截或装饰器模式,都必须通过.doFinally(s -> DataBufferUtils::release)进行终态兜底释放。 - 高并发下的连接/流异常中断
在面对极高并发或整合特定组件(如 Spring Redis Session)时,网络底层的偶发中断会导致部分响应流未能走完预设的生命周期(参考文末 Issue #664、#2384、#3033、#2377)。这不仅会抛出内存泄漏警告,在极端情况下还会直接触发OutOfDirectMemoryError。我在进行的 500 万次高并发压测中,我确实观察到了极小概率(小于 10 次)的 Netty 泄漏报错,这说明偶发网络异常也是泄漏推手之一。
综合来看,这类问题本质上是由复杂的响应式链路、异常流中断以及 Gateway 自身过滤链处理机制交织导致的底层内存引用计数未能彻底清零。
4. 解决方案与实施策略
排查至此,在短期内团队无法对当前项目进行破坏性依赖升级(如跨大版本升级 Gateway 以获取官方补丁)的前提下,我决定从 Netty 的底层内存分配策略层面进行干预。
针对这种由极小概率的流中断或深层框架缺陷引起的缓慢泄漏,我通过在 JVM 启动参数中追加以下配置,将 Netty 的内存分配器强制更改为非池化模式:
1 | -Dio.netty.allocator.type=unpooled |
4.1 架构层面的权衡与风险说明
在实施这一策略时,必须清晰认知其背后的得失权衡:
池化(Pooled) 是 Netty 默认的分配器策略(PooledByteBufAllocator)。它通过预先申请一大块直接内存作为池子,并使用引用计数机制来复用内存块。这大幅降低了昂贵的直接内存申请系统调用,并减轻了 JVM 的垃圾收集负担。但其致命弱点在于:只要有一块 ByteBuf 忘记释放(计数不为 0),这块内存就永远被锁定在池中,最终必然演变为 OutOfDirectMemoryError 内存溢出灾难。
非池化(Unpooled) 分配器(UnpooledByteBufAllocator)则会在每次需要内存时向操作系统申请全新的直接内存块,使用完毕后依靠 JVM 的 Cleaner 机制随着垃圾回收一同清理。这从物理机制上彻底绕过了引用计数带来的池泄漏死锁。即便是流异常中断导致没有执行显式的 release(),只要该 ByteBuffer 对象失去强引用,JVM 就会在执行 GC 时触发对应的系统调用释放物理内存,从而确保可用内存的最终回收。
风险代价: 将分配器切换为非池化是一种典型的牺牲部分性能换取系统绝对稳定性的妥协策略。
- CPU 开销显著增加:由于直接内存的申请与释放涉及昂贵的 OS 内核态切换与系统调用,高并发下将带来更高的 CPU 负载。
- GC 停顿频发:大量短生命周期的直接内存分配会产生海量的
DirectByteBuffer句柄对象,加剧了 JVM 垃圾收集器的压力,并可能引起更频繁、甚至更耗时的垃圾收集停顿(STW)。
实测评估表明,在当前业务的 QPS 流量模型下,系统性能的轻微衰退在可接受范围内。
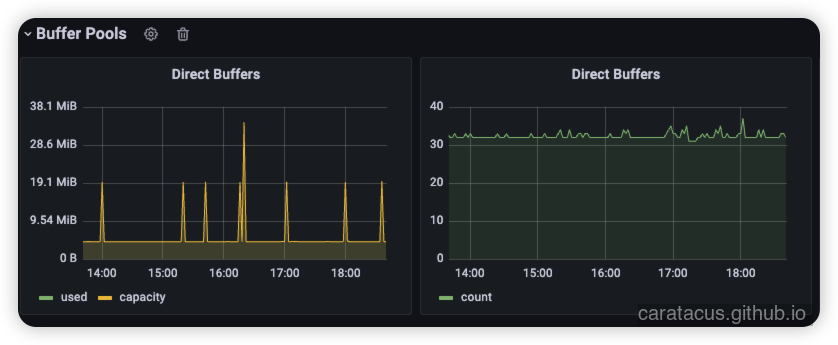
应用该参数后,监控数据反馈了预期的平稳态势。从折线图可以看到,Direct Memory 的水位线呈现出健康的锯齿状波动,能够随着垃圾收集周期被稳定释放,不再呈现单调递增的死锁趋势。
5. 复盘与架构演进反思
本次冗长且曲折的堆外内存泄漏排查,暴露出自己在响应式编程架构下的诸多认知盲区。
Netty 基于引用计数池化的直接内存生命周期管理机制,在常规的同步阻塞框架下尚能较好掌控,但一旦与 WebFlux 高度抽象的异步非阻塞流结合,便成为了一头难以驾驭的巨兽。在操作 DataBuffer 时,必须将”谁消费、谁释放”的原则刻录在每一行代码的潜意识中。
更加隐蔽的是,仅仅关注主流程(Happy Path)的资源释放是远远不够的。复杂的网络环境意味着流随时可能因为客户端中断、下游服务熔断、或是深层组件的异常抛出而被迫中止。若无法做到针对每一种潜在异常的 try-finally 或使用响应式的 doFinally 兜底,每一次异常中断都会将系统推进一步走向堆外内存耗尽的深渊。
后续计划在现有的开发规范中引入更严格的静态代码检查规则,同时推进基础设施层的升级。将业务逻辑与基础设施代码进一步解耦,以减少业务系统直面底层 DataBuffer 管理带来的心智负担与风险。
参考资料
- Reactor Netty Issue #1188: HttpClient: LEAK: ByteBuf.release() was not called before it’s garbage-collected
- Reactor Netty Issue #2377: Memory leak when using with spring redis session
- Reactor Netty Issue #2384: LEAK: ByteBuf.release() in Spring Cloud Gateway
- Spring Cloud Gateway Issue #664: Memory leak and sockets leak issue & OutOfDirectMemoryError
- Spring Cloud Gateway Issue #2408: Memory Leak on cached Request Body
- Spring Cloud Gateway Issue #2672: Memory leak causing bytebuffer to have no specific pointer
- Spring Cloud Gateway Issue #3033: Memory LEAK: ByteBuf.release() pointing to reactiveBridge
- Spring Cloud Gateway Issue #3376: LEAK: ByteBuf.release() error with ModifyRequestBody
- Spring Cloud Gateway Issue #3797: Help debug LEAK: ByteBuf.release() in custom filter